本文共 2420 字,大约阅读时间需要 8 分钟。
一、 概述
阿里云产品种类繁多,今天让我们一起来瞧瞧表格存储(Table Store)吧。
什么是表格存储呢?
简单来说,表格存储是构建在阿里云飞天分布式系统之上的NoSQL数据存储服务,提供海量结构化数据的存储和实时访问。表格存储以实例和表的形式组织数据,通过数据分片和负载均衡技术,实现规模上的无缝扩展。应用通过调用表格存储 API / SDK 或者操作管理控制台来使用表格存储服务。
那么,表格存储有什么优势呢?
- 表格存储具有很好的扩展性。应用在创建表的时候,需要根据业务访问的情况来配置预留读/写吞吐量。Table Store根据表的预留读/写吞吐量进行资源的调度和预留,从而保证应用获得可预期的性能。在使用过程中,应用还可以根据应用的情况动态修改预留读/写吞吐量。Table Store表的数据量没有上限,随着表数据量的不断增大,Table Store会进行数据分区的调整从而为该表配置更多的存储。
- 表格存储在数据可靠性上也是值得信赖的。Table Store通过存储多个数据备份及备份失效时的快速恢复,提供极高的数据可靠性。
- 表格存储具备高可用性。通过自动的故障检测和数据迁移,Table Store对应用屏蔽了机器和网络的硬件故障,提供高可用性。
- 表格存储管理便捷,对应用的每一次请求都进行身份认证和鉴权,以防止未授权的数据访问,确保数据访问的安全性。
- 表格存储保证数据写入强一致,写操作一旦返回成功,应用就能立即读到最新的数据。
- Table Store的表无固定格式要求,每行的列数可以不相同,支持多种数据类型(Integer、Boolean、Double、String、Binary)。
此外,表格存储根据用户预留和实际使用的资源进行收费,起步门槛低。用户可以从Table Store控制台实时获取每秒请求数、平均响应延时等监控信息。
目前,施耐德、够快等都在使用表格存储。
表格存储典型特性介绍:
二、 技术点(表格存储五大热点技术问题分析)
在上一篇文章中,我们为大家介绍表格存储的概况,表格存储(Table Store)是构建在阿里云飞天分布式系统之上的NoSQL数据存储服务,提供海量结构化数据的存储和实时访问。那在使用过程中,经常遇到的热门技术问题有哪些呢?
控制台使用:
数据表管理:
表格存储TableStore支持的操作:
表格存储Table Store-建表时的注意事项:
Table Store 表的最佳实践:
希望上面的内容,能够对大家有所帮助。
三、 体验(表格存储结合Elasticsearch构建爬虫搜索引擎)
今天给大家带来一篇技术文章,结合表格存储和Elasticsearch构建一个爬虫搜索引擎,非常有意思。只需要简单的几个命令即可构建一个Demo,欢迎感兴趣的人尝试。
Elasticsearch是一个实时分布式搜索和分析引擎,它的索引和搜索功能非常强大,所以使用场景很丰富。Elasticsearch基于Lucene,Lucene是一个非常复杂的搜索引擎库,而Elasticsearch提供的是更易用的一体化的分布式实时搜索应用。
下面就来一起看一下吧。
目标:爬取特定网站的页面,将页面内容保存在TableStore中,在Elasticsearch中建立网站的索引,通过web页面搜索框的形式,对爬取的页面进行搜索。
以天涯论坛为例,一套简单的方案:
爬取天涯论坛的帖子页面,提取的信息包括Url,标题,帖子内容。数据首先存入TableStore中,主键为随机的一个UUID,同时将Url、标题、帖子内容、UUID导入Elasticsearch中建立索引,Elasticsearch只保存Url、标题和UUID,不保存帖子内容。同时构建一个网页,通过搜索框输入关键词,在Elasticsearch中搜索获取结果。
1. 整个方案涉及四个模块:TableStore、Elasticsearch、Spider、Web。
2. TableStore不需要搭建,只需要开通服务、建表即可。我们使用TableStore来存取页面数据,每个页面的数据保存为TableStore的一行,使用UpdateRow写入,使用GetRow读出。
3. Elasticsearch需要在ECS中搭建起来,搭建Elasticsearch非常简单,只需要下载下来运行启动脚本即可。与TableStore建表类似,在搭建完成Elasticsearch之后,需要在Elasticsearch中建立索引(Index),并需要在索引上建立映射(Mapping)。
4. Spider具体爬取页面,我们选取了一个简单易用的开源爬虫软件,WebMagic。使用WebMagic的接口,我们可以方便的把爬取的页面数据存入TableStore和Elasticsearch。
5. Web指网页搜索的前后端。出于开发效率的考虑,我们选择一些接口简单易用的工具进行开发,后端使用一个Python的web框架flask,前端使用vue.js。
快速部署与体验
1. 项目代码解压后结构如下所示, 请先阅读README.md文件:
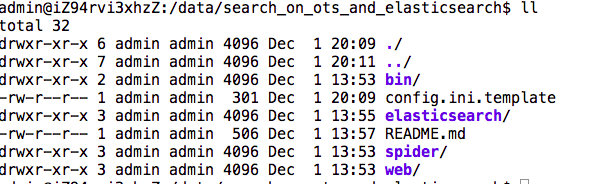
2.执行以下命令生成配置文件:
cp config.ini.template config.ini
3.修改配置文件,填入endpoint, accessid, accesskey, instancename等信息,需要在阿里云官网开通表格存储服务,然后创建实例。
4. 安装相关软件。
5. 初始化:
启动Elasticsearch。
初始化TableStore表和Elasticsearch索引。
6. 运行爬虫。
7. 运行搜索Web界面。
8. 访问:
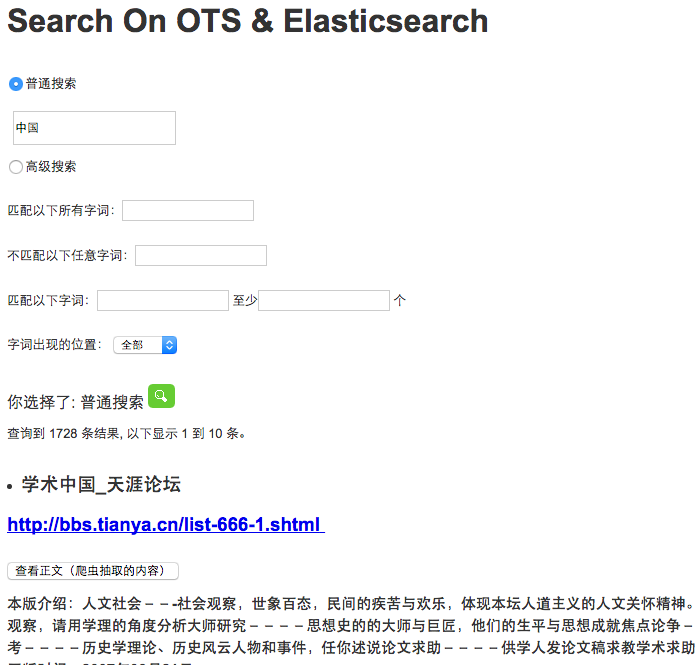
以上就是我使用表格存储的部分经验,希望大家有所收获。
如果您想详细了解表格存储,请访问:
深入浅出OTS
OTS Java SDK优化实践:
转载地址:http://obhtx.baihongyu.com/